Learning Long Term Style Preserving Blind Video Temporal Consistency

Abstract
When trying to independently apply image-trained algorithms to successive frames in videos, noxious flickering tends to appear. State-of-the-art post-processing techniques that aim at fostering temporal consistency, generate other temporal artifacts and visually alter the style of videos. We propose a post-processing model, agnostic to the transformation applied to videos (e.g. style transfer, image manipulation using GANs, etc.), in the form of a recurrent neural network. Our model is trained using a Ping Pong procedure and its corresponding loss, recently introduced for GAN video generation, as well as a novel style preserving perceptual loss. The former improves long-term temporal consistency learning, while the latter fosters style preservation. We evaluate our model on the DAVIS and videvo.net datasets and show that our approach offers state-of-the-art results concerning flicker removal, and better keeps the overall style of the videos than previous approaches.
Paper & Supplementary Materials

Learning Long Term Style Preserving Bling Video Temporal Consistency.
ICME, 2021 (Main Track, Oral) [arXiv] [BibTeX] [Supplementary Materials]
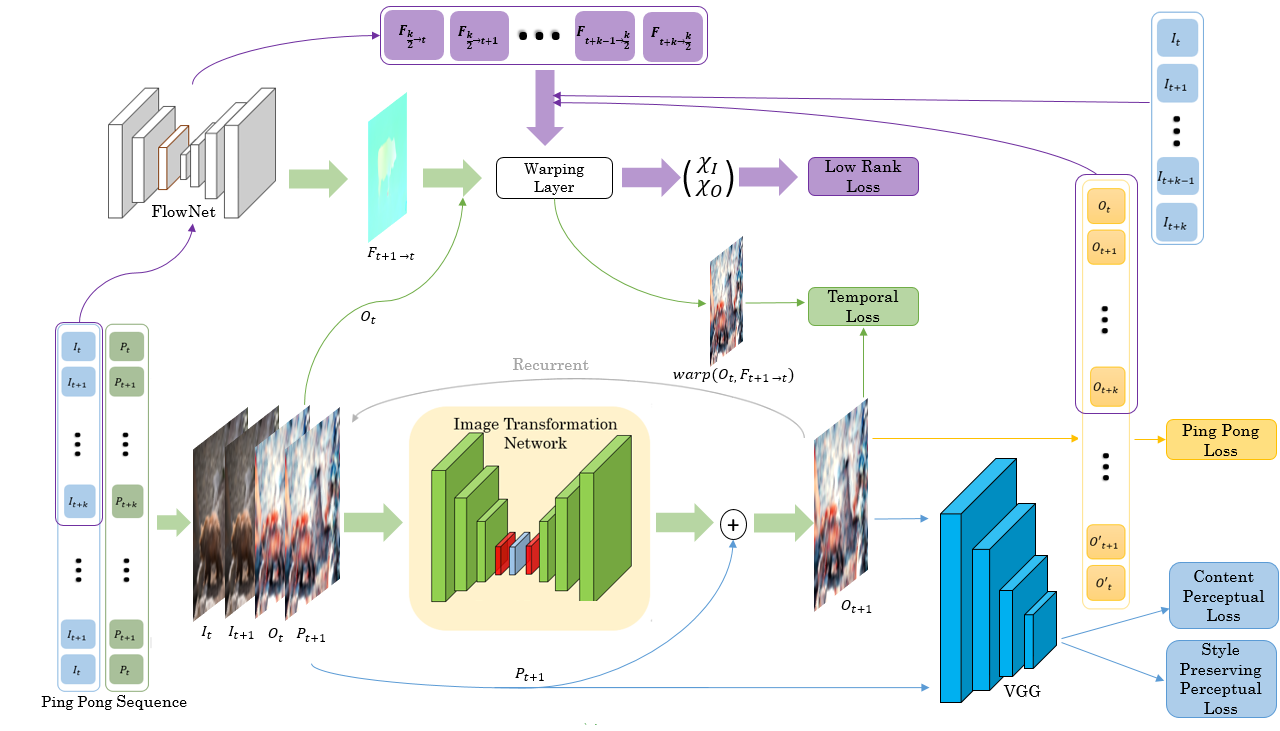
Model
Let us denote the original unprocessed frames {It}t=1,…T, the per-frame processed videos {Pt}t=1,…T
and {Ot}t=1,…T the corresponding outputs of the model. Our model receives as input two sequences of frames of fixed length k, {It,It+1,…,It+k} the original unprocessed frames and {Pt,Pt+1,…,Pt+k} the processed frames using any transformation algorithms (
Training
To train our model, we use two types of losses composed of six different losses: (i) Perceptual Losses : Lp to ensure perceptual resemblence between the input and output frames, LSP for style preservation, (ii) Temporal Losses : LPP and Lrank for both short term and long term temporal consistency, Lst for short-term temporal consistency and Llt for long-term temporal consistency.
Results
Videvo.net and DAVIS datasets
The height of each video in the training set is scaled to 480 while preserving the aspect ratio. The training set contains in total 25,735 frames. The applications considered in the dataset are the following: artistic style transfer, Colorization, Image enhancement, Intrinsic image decomposition, and Image-to-image translation.
The videos below display test set videos comparison between raw processed videos vs our post-processed model, but also our postprocessing model vs Lai et al. (2018) postprocessing model.
Ping Pong Loss
The use of the Ping Pong Loss allows to correct temporal artefacts appearing using the post-processing the model of Lai et al. (2018). For instance, the following video was processed using makeup synthesis (lipstick) and post-processed using Lai et al. (2018) which removes the lip flickering but at the cost of a red trail following the lips as the head moves. Our model on the contrary manages to remove flickering without generating any trail.
Style Preserving Perceptual Loss
The style preserving perceptual loss reduces deterioration of the brightness throughout videos and style deviation. For instance, both our model and the model of Lai et al. (2018) can alter the brightness of videos and our proposed loss manages to reduce such issue as seen in the following video.
Other works
Check out our other papers presented at AIM (ECCV 2020): https://despoisj.github.io/AgingMapGAN/ https://robinkips.github.io/CA-GAN/