
Hugo Thimonier, PhD
Applied AI Scientist, Mistral
I am currently an Applied AI Scientist at Mistral working on multimodal LLMs. I hold a PhD in Computer Science from CentraleSupélec and the LISN Lab. My current research interest ranges from Anomaly detection, Self-supervised Learning, Deep Learning for tabular data, and multimodal LLMs. I have received an MSc degree in Statiscial Engineering from ENSAE and studied as a Normalien at ENS Paris-Saclay.
News
Research
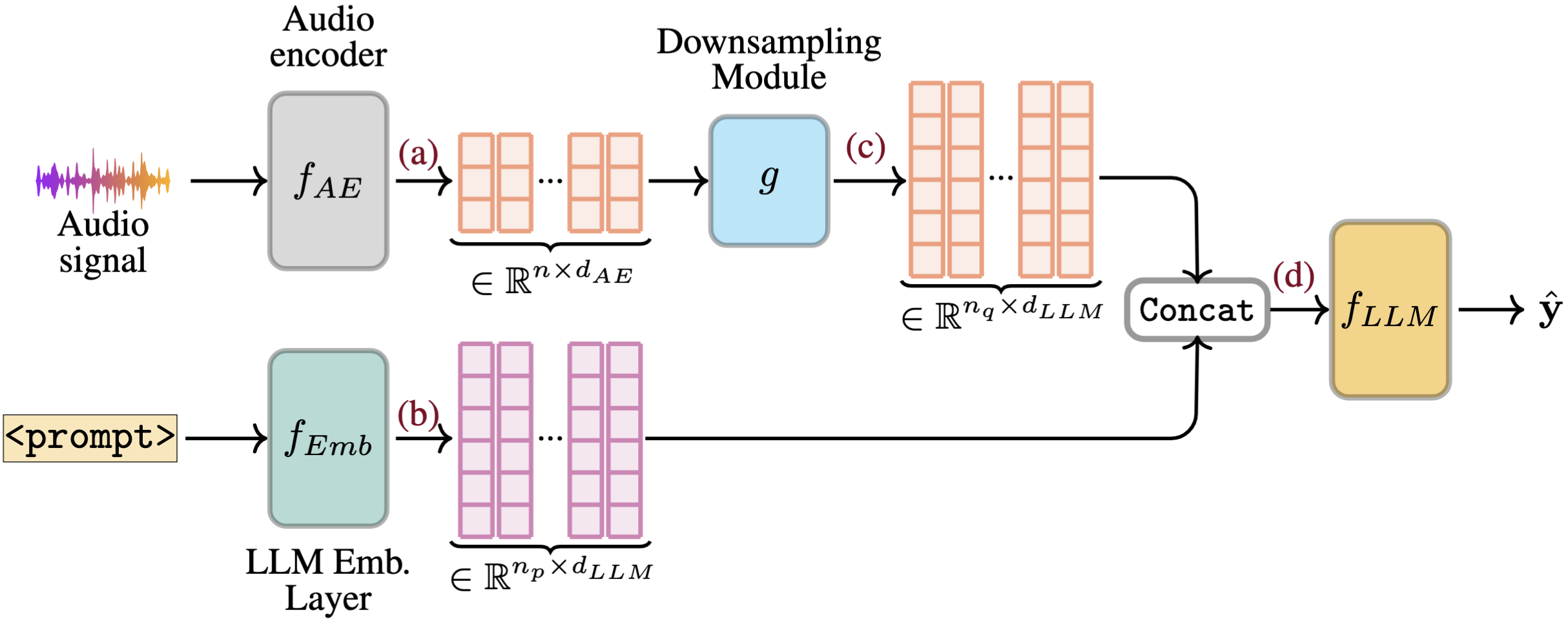
NeurIPS Workshop on Multimodal Representation Learning for Healthcare, 2025.
@inproceedings{thimonier2025emosllmparameterefficientadaptationllms,
title={{EmoSLLM}: Parameter-Efficient Adaptation of {LLM}s for Speech Emotion Recognition},
author={Hugo Thimonier and Antony Perzo and Renaud Seguier},
year={2025},
booktitle={NeurIPS Workshop on Multimodal Representation Learning for Healthcare},
year={2025},
url={https://openreview.net/forum?id=huMNytWWaq}
}
Emotion recognition from speech is a challenging task that requires capturing both linguistic and paralinguistic cues, with critical applications in human-computer interaction and mental health monitoring. Recent works have highlighted the ability of Large Language Models (LLMs) to perform tasks outside of the sole natural language area. In particular, recent approaches have investigated coupling LLMs with other data modalities by using pre-trained backbones and different fusion mechanisms. This work proposes a novel approach that fine-tunes an LLM with audio and text representations for emotion prediction. Our method first extracts audio features using an audio feature extractor, which are then mapped into the LLM's representation space via a learnable interfacing module. The LLM takes as input (1) the transformed audio features, (2) additional features in the form of natural language (e.g., the transcript), and (3) a textual prompt describing the emotion prediction task. To efficiently adapt the LLM to this multimodal task, we employ Low-Rank Adaptation (LoRA), enabling parameter-efficient fine-tuning. Experimental results on standard emotion recognition benchmarks demonstrate that our model outperforms all but one existing Speech-Text LLMs in the literature, while requiring less than half the parameters of competing approaches. This highlights our approach's effectiveness in integrating multi-modal inputs for speech-based emotion understanding while maintaining significant computational efficiency.
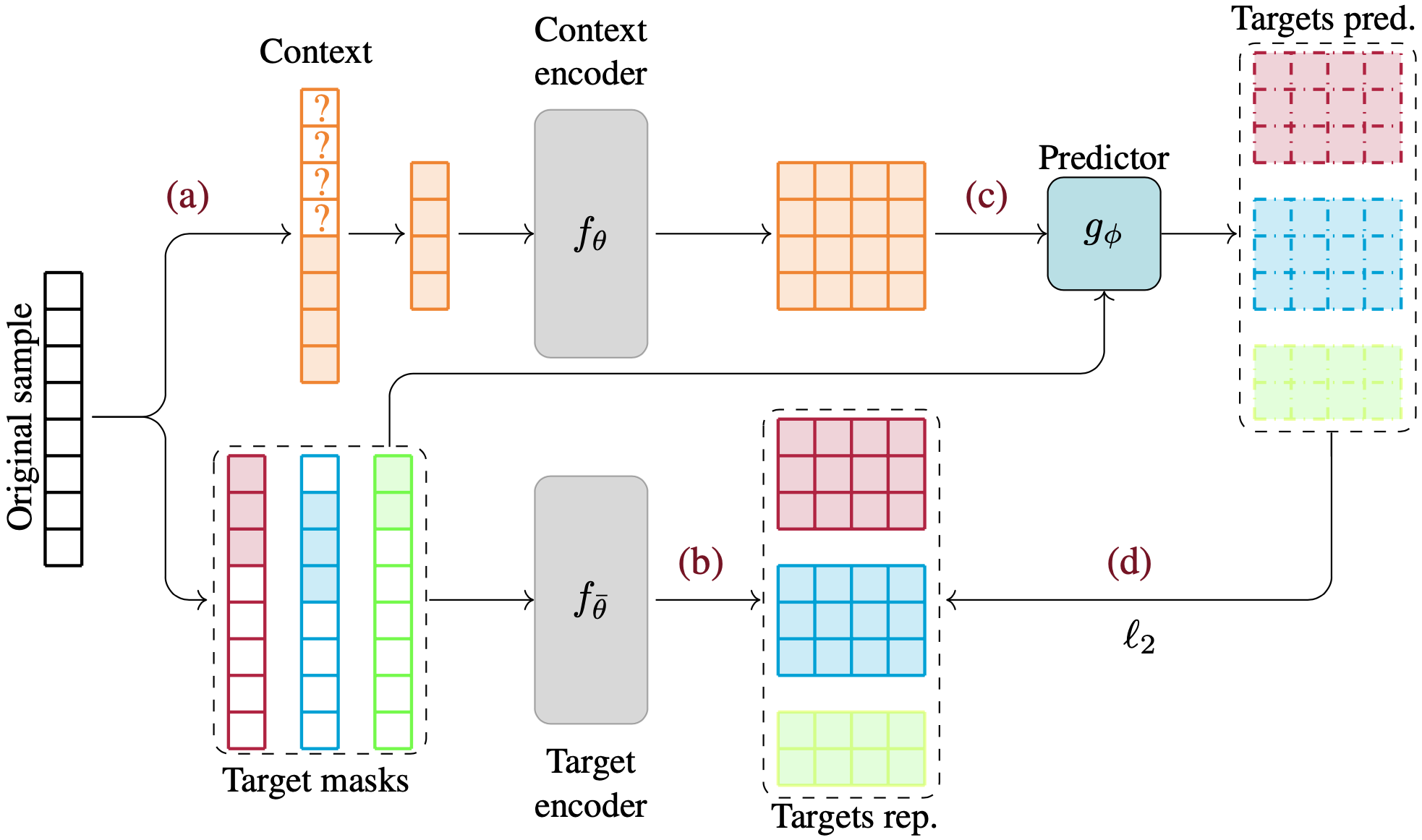
Thirteenth International Conference on Learning Representations, ICLR 2025.
@inproceedings{thimonier2025tjepa,
title={T-JEPA: Augmentation-Free Self-Supervised Learning for Tabular Data},
author={Hugo Thimonier and José Lucas De Melo Costa and Fabrice Popineau and Arpad Rimmel and Bich-Liên Doan},
booktitle={The Thirteenth International Conference on Learning Representations},
year={2025},
url={https://openreview.net/forum?id=gx3LMRB15C}
}
Self-supervision is often used for pre-training to foster performance on a downstream task by constructing meaningful representations of samples. Self-supervised learning (SSL) generally involves generating different views of the same sample and thus requires data augmentations that are challenging to construct for tabular data. This constitutes one of the main challenges of self-supervision for structured data. In the present work, we propose a novel augmentation-free SSL method for tabular data. Our approach, T-JEPA, relies on a Joint Embedding Predictive Architecture (JEPA) and is akin to mask reconstruction in the latent space. It involves predicting the latent representation of one subset of features from the latent representation of a different subset within the same sample, thereby learning rich representations without augmentations. We use our method as a pre-training technique and train several deep classifiers on the obtained representation. Our experimental results demonstrate a substantial improvement in both classification and regression tasks, outperforming models trained directly on samples in their original data space. Moreover, T-JEPA enables some methods to consistently outperform or match the performance of traditional methods likes Gradient Boosted Decision Trees. To understand why, we extensively characterize the obtained representations and show that T-JEPA effectively identifies relevant features for downstream tasks without access to the labels. Additionally, we introduce regularization tokens, a novel regularization method critical for training of JEPA-based models on structured data.
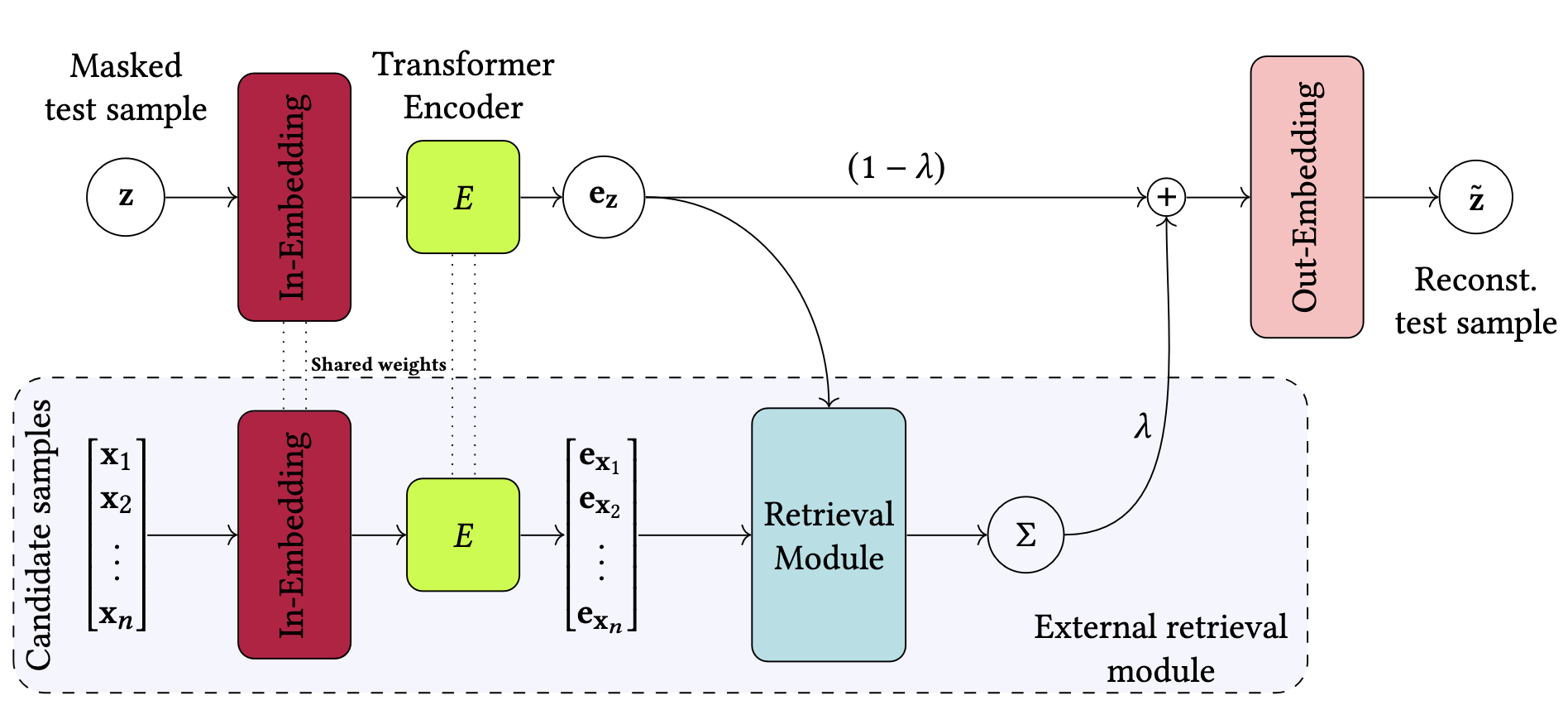
33rd ACM International Conference on Information and Knowledge Management, CIKM '24.
@inproceedings{thimonier2024making,
series={CIKM ’24},
title={Retrieval Augmented Deep Anomaly Detection for Tabular Data},
volume={35},
url={http://dx.doi.org/10.1145/3627673.3679559},
DOI={10.1145/3627673.3679559},
booktitle={Proceedings of the 33rd ACM International Conference on Information and Knowledge Management},
publisher={ACM},
author={Thimonier, Hugo and Popineau, Fabrice and Rimmel, Arpad and Doan, Bich-Liên},
year={2024},
month=oct,
pages={2250–2259},
collection={CIKM ’24}
}
Deep learning for tabular data has garnered increasing attention in recent years, yet employing deep models for structured data remains challenging. While these models excel with unstructured data, their efficacy with structured data has been limited. Recent research has introduced retrieval-augmented models to address this gap, demonstrating promising results in supervised tasks such as classification and regression. In this work, we investigate using retrieval-augmented models for anomaly detection on tabular data. We propose a reconstruction-based approach in which a transformer model learns to reconstruct masked features of normal samples. We test the effectiveness of KNN-based and attention-based modules to select relevant samples to help in the reconstruction process of the target sample. Our experiments on a benchmark of 31 tabular datasets reveal that augmenting this reconstruction-based anomaly detection (AD) method with sample-sample dependencies via retrieval modules significantly boosts performance. The present work supports the idea that retrieval module are useful to augment any deep AD method to enhance anomaly detection on tabular data.
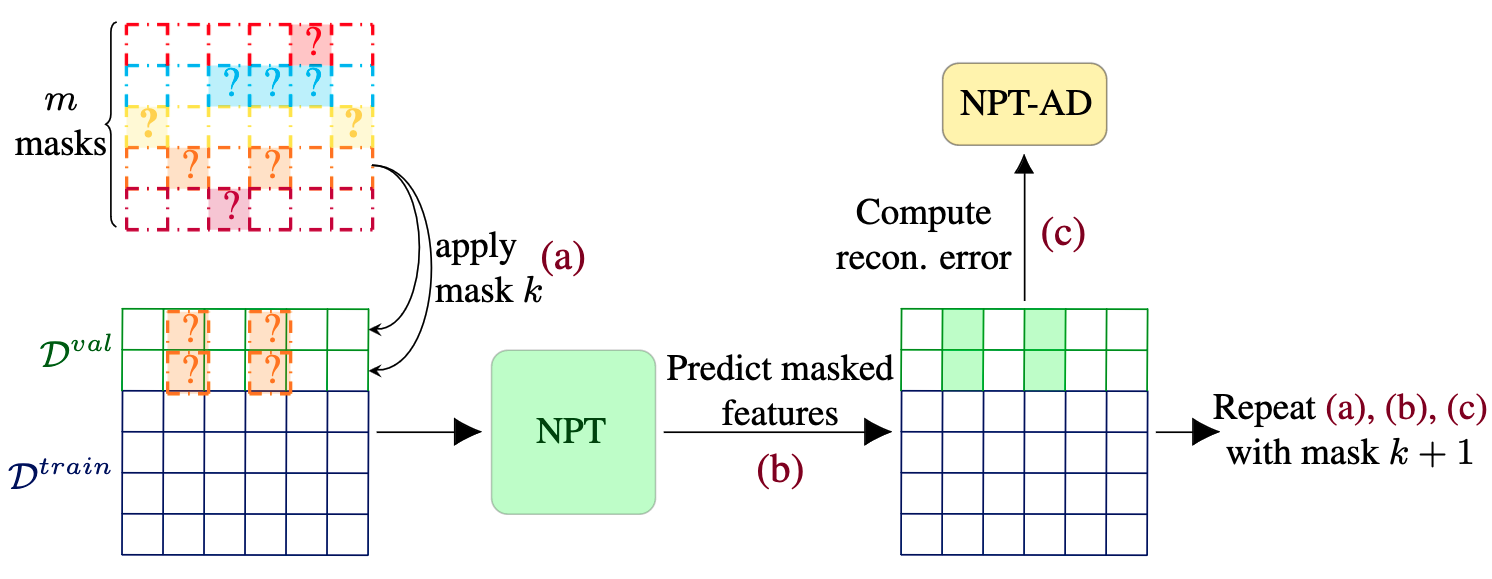
41st International Conference on Machine Learning, ICML 2024.
@InProceedings{pmlr-v235-thimonier24a,
title = {Beyond Individual Input for Deep Anomaly Detection on Tabular Data},
author = {Thimonier, Hugo and Popineau, Fabrice and Rimmel, Arpad and Doan, Bich-Li\^{e}n},
booktitle = {Proceedings of the 41st International Conference on Machine Learning},
pages = {48097--48123},
year = {2024},
editor = {Salakhutdinov, Ruslan and Kolter, Zico and Heller, Katherine and Weller, Adrian and Oliver, Nuria and Scarlett, Jonathan and Berkenkamp, Felix},
volume = {235},
series = {Proceedings of Machine Learning Research},
month = {21--27 Jul},
publisher = {PMLR},
pdf = {https://raw.githubusercontent.com/mlresearch/v235/main/assets/thimonier24a/thimonier24a.pdf},
url = {https://proceedings.mlr.press/v235/thimonier24a.html},
}
Anomaly detection is vital in many domains, such as finance, healthcare, and cybersecurity. In this paper, we propose a novel deep anomaly detection method for tabular data that leverages Non-Parametric Transformers (NPTs), a model initially proposed for supervised tasks, to capture both feature-feature and sample-sample dependencies. In a reconstruction-based framework, we train the NPT to r econstruct masked features of normal samples. In a non-parametric fashion, we leverage the whole training set during inference and use the model's ability to reconstruct the masked features to generate an anomaly score. To the best of our knowledge, this is the first work to successfully combine feature-feature and sample-sample dependencies for anomaly detection on tabular datasets. Through extensive experiments on 31 benchmark tabular datasets, we demonstrate that our method achieves state-of-the-art performance, outperforming existing methods by 2.4% and 1.2% in terms of F1-score and AUROC, respectively. Our ablation study provides evidence that modeling both types of dependencies is crucial for anomaly detection on tabular data.

International Joint Conference on Neural Networks, IJCNN 2022.
@inproceedings{thimonier2022,
author={Thimonier, Hugo and Popineau, Fabrice and Rimmel, Arpad and Doan, Bich-Liên and Daniel, Fabrice},
booktitle={2022 International Joint Conference on Neural Networks (IJCNN)},
title={{TracInAD}: Measuring Influence for Anomaly Detection},
year={2022},
volume={},
number={},
pages={1-6},
doi={10.1109/IJCNN55064.2022.9892058}
}
As with many other tasks, neural networks prove very effective for anomaly detection purposes. However, very few deep-learning models are suited for detecting anomalies on tabular datasets. This paper proposes a novel methodology to flag anomalies based on TracIn, an influence measure initially introduced for explicability purposes. The proposed methods can serve to augment any unsupervised deep anomaly detection method. We test our approach using Variational Autoencoders and show that the average influence of a subsample of training points on a test point can serve as a proxy for abnormality. Our model proves to be competitive in comparison with state-of-the- art approaches: it achieves comparable or better performance in terms of detection accuracy on medical and cyber-security tabular benchmark data.
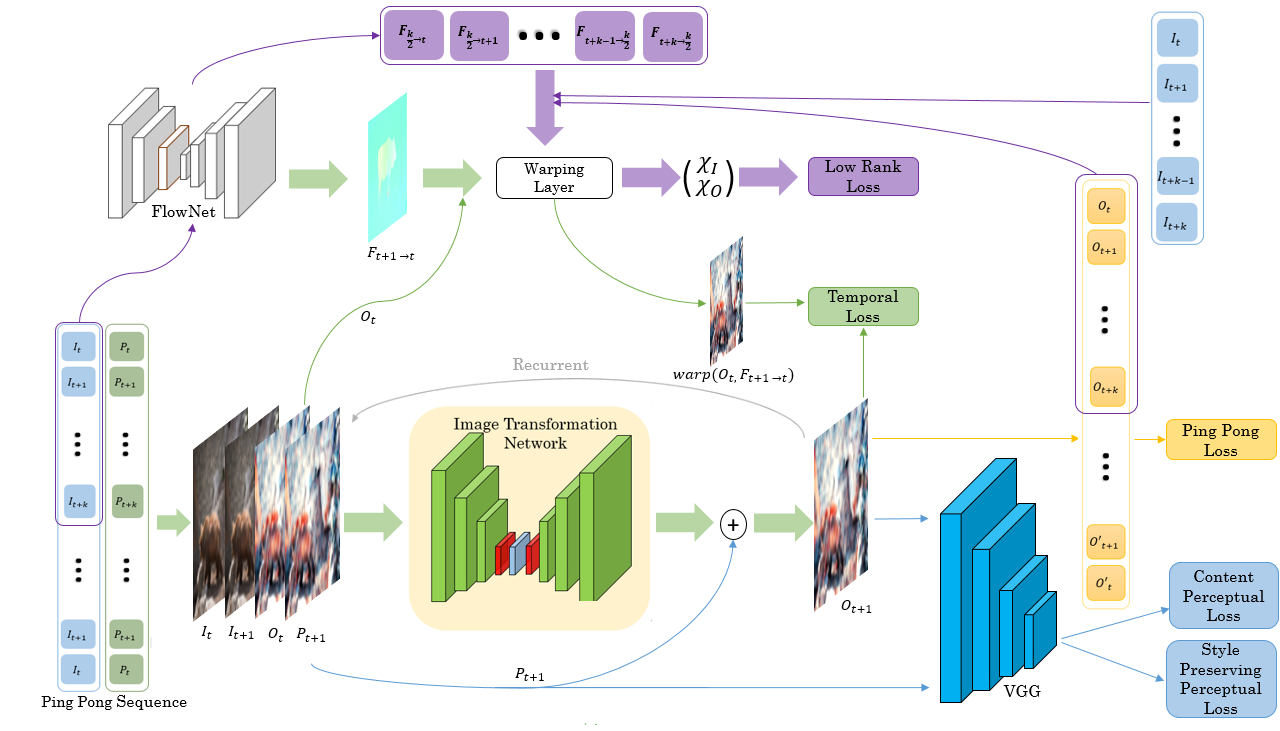
IEEE International Conference on Multimedia and Expo, ICME 2021.
@inproceedings{thimonier2021,
author={Thimonier, Hugo and Despois, Julien and Kips, Robin and Perrot, Matthieu},
booktitle={2021 IEEE International Conference on Multimedia and Expo (ICME)},
title={Learning Long Term Style Preserving Blind Video Temporal Consistency},
year={2021},
volume={},
number={},
pages={1-6},
doi={10.1109/ICME51207.2021.9428445}
}
When trying to independently apply image-trained algorithms to successive frames in videos, noxious flickering tends to appear. State-of-the-art post-processing techniques that aim at fostering temporal consistency, generate other temporal artifacts and visually alter the style of videos. We propose a post- processing model, agnostic to the transformation applied to videos (e.g. style transfer, image manipulation using GANs, etc.), in the form of a recurrent neural network. Our model is trained using a Ping Pong procedure and its corresponding loss, recently introduced for GAN video generation, as well as a novel style preserving perceptual loss. The former improves long-term temporal consistency learning, while the latter fosters style preservation. We evaluate our model on the DAVIS and videvo.net datasets and show that our approach offers state-of-the-art results concerning flicker removal, and better keeps the overall style of the videos than previous approaches.